



【亿邦原创】又一家科技巨头加入开源行列。
8月3日,AI模型社区魔搭ModelScope上架两款开源模型Qwen-7B和Qwen-7B-Chat,阿里云确认其为通义千问70亿参数通用模型和对话模型,两款模型均开源、免费、可商用。
此前,国内曾有清华大学、复旦大学、百川智能先后开源ChatGLM-6B、MOSS及Baichuan-7B;国外开源生态更为积极,今年2年24日Meta发布LLaMA开源大模型后,Alpaca、Vicuna、Koala等多个大模型诞生,它们以远低于ChatGPT的规模和成本,降低了AI商用门槛,扩展了商业可用性。
1、70亿参数模型上线魔搭社区,免费可商用
本次开源的通义千问7B模型,号称达到了当下业界最强的中英文7B开源模型。
据介绍,Qwen-7B是支持中、英等多种语言的基座模型,在超过2万亿token数据集上训练,上下文窗口长度达到8k。
Qwen-7B-Chat是基于基座模型的中英文对话模型,已实现与人类认知对齐。开源代码支持对Qwen-7B和Qwen-7B-Chat的量化,支持用户在消费级显卡上部署和运行模型。
用户既可从魔搭社区直接下载模型,也可通过阿里云灵积平台访问和调用Qwen-7B和Qwen-7B-Chat,阿里云为用户提供包括模型训练、推理、部署、精调等在内的全方位服务。
图片来源:阿里云官网
阿里云准备充分,还公布了Qwen-7B的各项测评结果。
在英文能力测评基准MMLU上,通义千问7B模型得分超过一众7B、12B、13B主流开源模型。该基准包含57个学科的英文题目,考验人文、社科、理工等领域的综合知识和问题解决能力。
在中文常识能力测评基准C-Eval上,通义千问在验证集和测试集中都是得分最高的7B开源模型,展现了扎实的中文能力。
在数学解题能力评测GSM8K、代码能力评测HumanEval等基准上,通义千问7B模型也有不俗表现,胜过所有同等尺寸开源模型和和部分大尺寸开源模型。
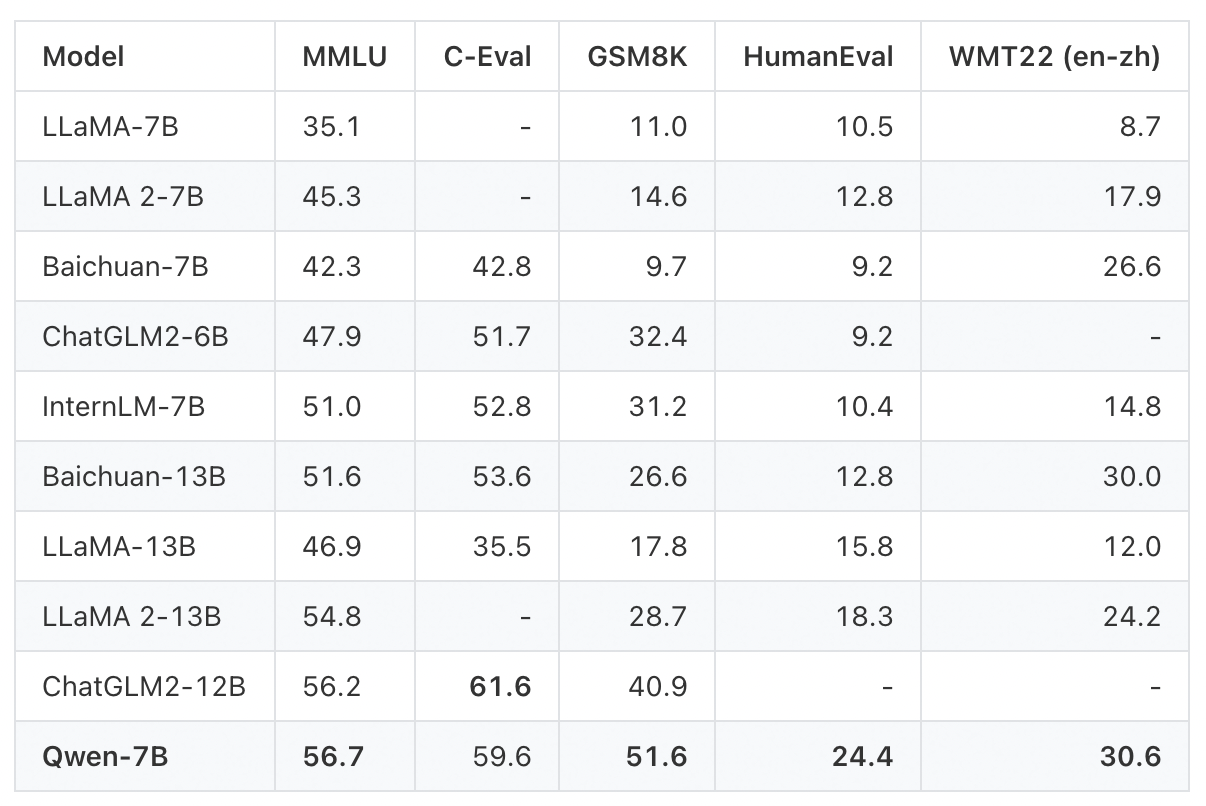
图片来源:阿里云官网
阿里云表示,开源大模型可以帮助用户简化模型训练和部署的过程,用户不必从头训练模型,只需下载预训练好的模型并进行微调,就可快速构建高质量的模型。
2、大模型小型化趋势明显
大模型开源的原因可以简单概括为:更低的算力成本、更好的数据安全、更普惠的AI应用。
在大模型的训练和使用中,算力消耗分为两部分场景:训练成本消耗与推理成本消耗。开源大模型主要节省了企业预训练阶段的算力,降低模型参数体量则降低了企业在使用模型时的推理成本。
开源大模型还允许开发人员进行定制化开发,定向训练数据,可以针对某些主题进行过滤,减少模型体量和数据的训练成本。
相较于GPT系列的千亿参数超大模型,当下开源大模型的参数量普遍在十亿至百亿级别。
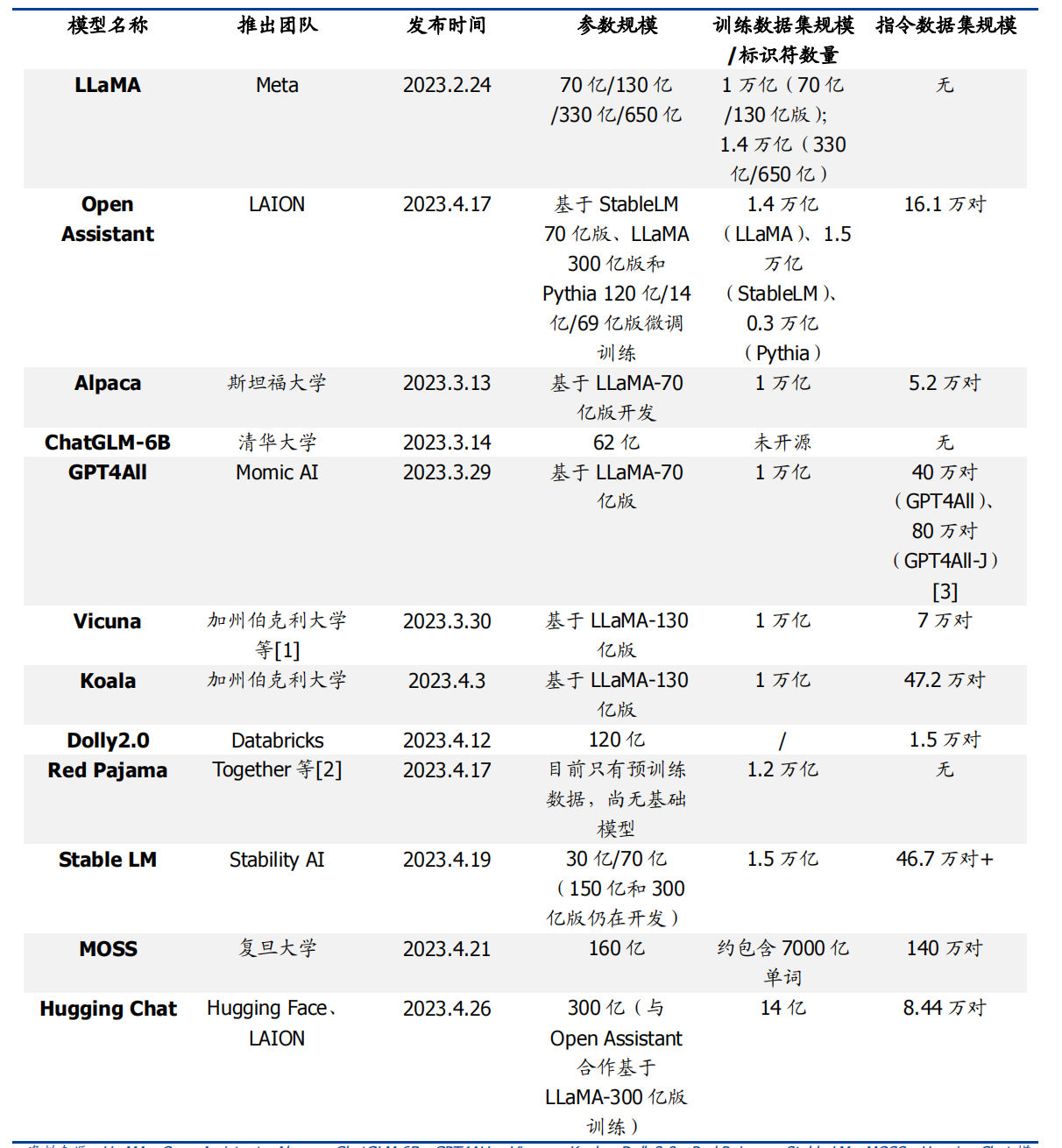
图片来源:国盛证券
在此前的6月15日,百川智能发布70亿参数量的中英文语言模型Baichuan-7B。7月11日,百川智能发布130亿参数通用大语言模型Baichuan-13B-Base,二者均为完全开源,免费可商用。
7月14日,智谱AI和清华KEG发布公告,ChatGLM-6B 和 ChatGLM2-6B 权重对学术研究完全开放,并且在完成企业登记获得授权后,允许免费商业使用。
对选择开源的科技企业而言,开源模型有利于快速打开市场,为潜在的商业化铺路。
开源社区汇聚大量研究机构和开发者,有利于加快模型优化和迭代,丰富应用端产品,中小厂商可以更专注于AIGC应用端的产品设计和创新。
今年7月,阿里云宣布将促进中国大模型生态的繁荣作为首要目标,向大模型创业公司提供智能算力、开发工具等全方位服务。目前,魔搭社区聚集了20多家顶尖人工智能机构贡献的1000多款开源模型。
大模型闭源与开源并存已成为行业共识,正如不少业内人士不约而同表示,闭源用一种大力出奇迹的方式证明路线可能性和天花板之后,开源把大模型变得易用和可用。
文章来源:亿邦动力






