



行业背景:
大宗领域与C 端场景不同,比如淘宝、支付宝的业务更多的是与个人相关,而大宗领域则是大型B2B交易,在数据上的表现是非常分散的,所面临的风险也与互联网场景完全不一样。我们前期面向国内头部大宗贸易型的企业做了大量的调研,如建发集团、厦门国贸,以及象屿股份,这几个都是营收规模可以达到5000亿的巨头企业。他们之前的业务模式大多是基于个人经验完成的,即依赖业务专家。
但是近几年国家在推行产业数字化升级,他们也开始向这个方向思考,有哪些数据可以应用?怎么应用?如何辅助业务风险判断?随着国内大宗商品企业规模效益凸显,利润率逐渐下行,“风险第一,利润第二,规模第三”成为普遍理念。
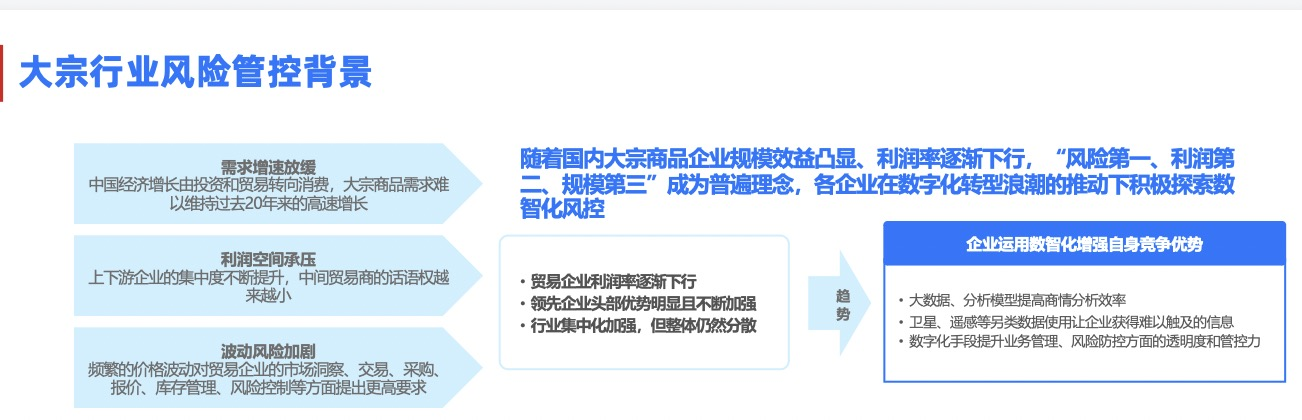
在这一背景下,推行大宗行业的数字化转型服务成为可能。就大宗行业自身而言,上游是各种原材料的供应商,如铁矿石、大豆、玉米、棉花等等,下游则是建筑公司、房地产公司、纺织厂等等。大宗贸易企业负责整合上下游客户需求,承担着贸易中介的角色。在这个过程中主要包括以下几类风险:
市场风险:近几年疫情的影响,以及国际形势的不稳定,导致大宗市场供应需求、流动性及价格的波动、汇率的变化,这些称作市场风险;
操作风险:大宗领域的业务合作是相对传统的B2B交易,这里面会包含大量的合同、品控、物流等需要关注的风险,称作操作风险;
信用风险:双方信用是交易保障的前提,评估上游供应商与下游客户的信用情况则尤为重要,所以信用风险是我们切入研究的一个主要场景,即如何通过数据来实现大宗行业上下游客商的信用评估。
大宗行业痛点
将原来在互联网场景,也就是C 端用户场景下数据应用的思路以及方法论,包括应用算法以及计算平台上的经验应用到传统行业里去,主要面临以下几个痛点:
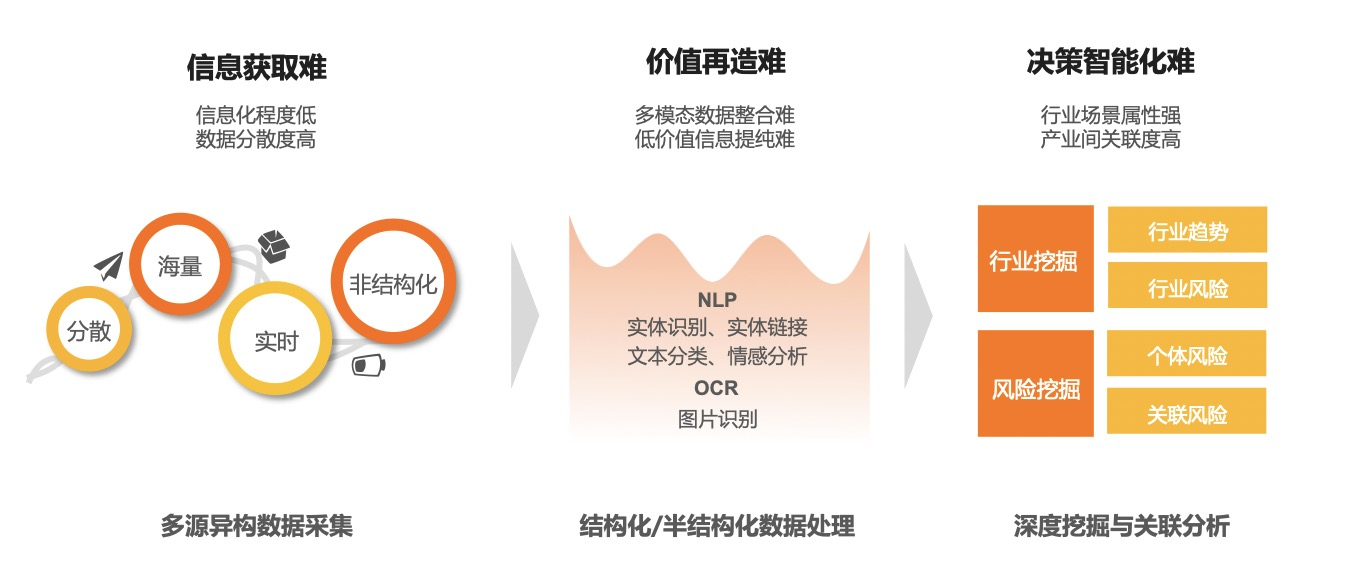
一是信息归集难,受限于整个行业数字化程度的影响,其中的数据非常分散,数据的规范性不足,还存在大量的非结构化数据,如纸质合同或扫描件、音视频等文件。同时,基于人为经验的业务操作未进行信息化沉淀。此外,业务员习惯人工线下定期去获取信息,比如仓库盘点、物流排查,较难转变为通过数字化手段来完成这些事情。
二是价值再造难,数据处理、关联关系梳理及高价值信息提取难。
三是决策智能化难,利用数据去适配业务场景,是非常需要深入到行业纵深去的,在这个行业,我们缺乏相关的资源投入与行业经验。简单理解就是个体本身的风险、个体和个体之间的关联风险,以及它所处的行业属性带来的风险差异性,比如零售卖水的行业和一个大宗的钢铁贸易的行业,它们的风险表现及数据呈现都是不一样的,所以数据应用的模式也是不一样的,这就导致在这种传统的To B领域做数据应用存在一定的挑战。
蚂蚁数科针对行业做了深入的调研与实践,结合几百家客户的合作和落地经历,沉淀了一些核心能力。
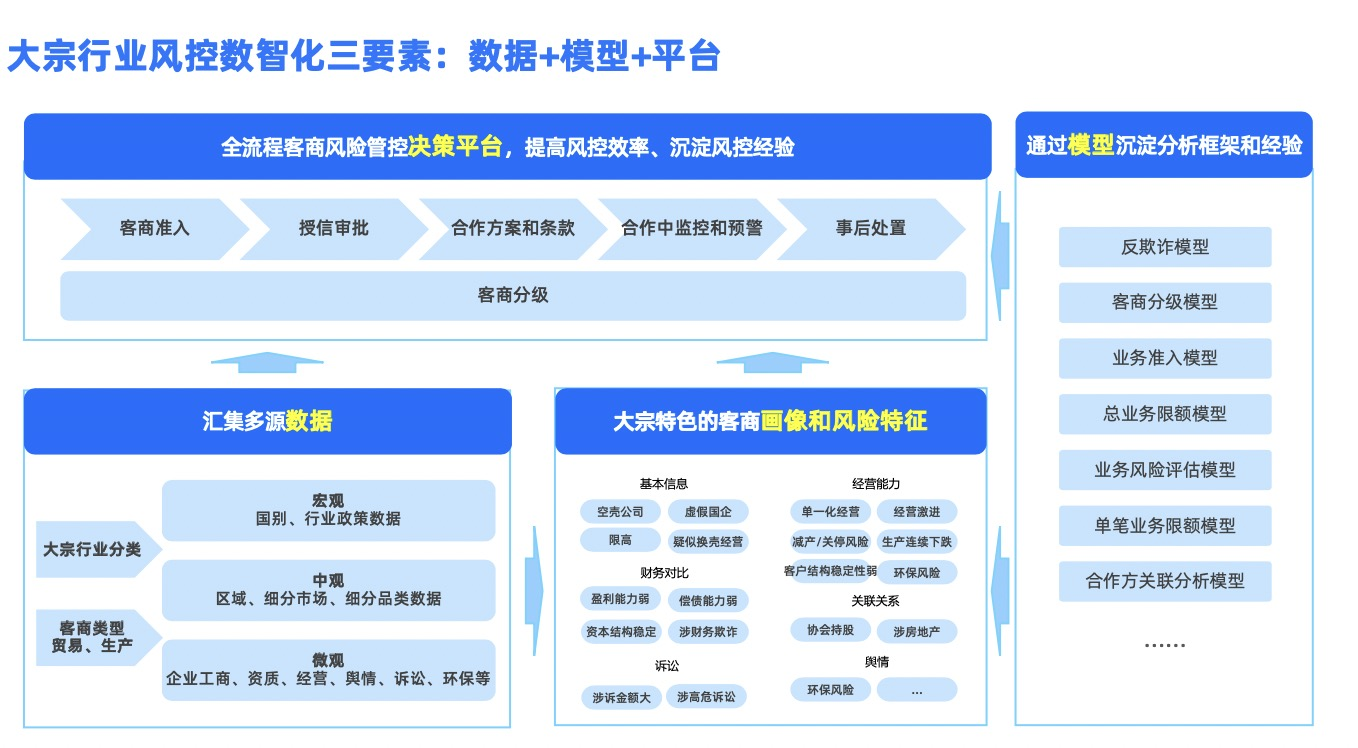
首先,在数据层面,要汇集多源数据。会把行业的一些宏观中观数据,与企业自身的微观信息进行整合,然后在此基础上构建围绕行业特有的信用风险所关注的维度,比如空壳、虚假国企,将财务相关的盈利性、偿债能力等一些具有行业属性的特征抽象出来,基于行业化的风险特征和画像,再去构建面向业务场景的数据模型。
整个业务流程会分为客商准入、客商的分类分级,合作的授信额度、合同风险异动的实时监控提醒等环节,这些业务环节中的风险监控都是需要用数据模型、算法及指标去支撑的。
目前蚂蚁数科已经形成了“数据+模型+平台”的一套解决方案。
在大宗业务中,针对三类角色,赋能三道业务防线:业务一线,为公司业务员在线下仓库进行风险尽调时提效;二是为公司的中后台部门,比如风险管理部门、客户管理部门,或运营管理部门,防范业务中的风险,提供一站式的客商风险管理平台,帮助他们进行整体的风险把控;三是帮助公司管理层开展整体的精细化运营。
接下来将分别从这几个维度,来探讨如何做好大宗领域的信用风险建设。
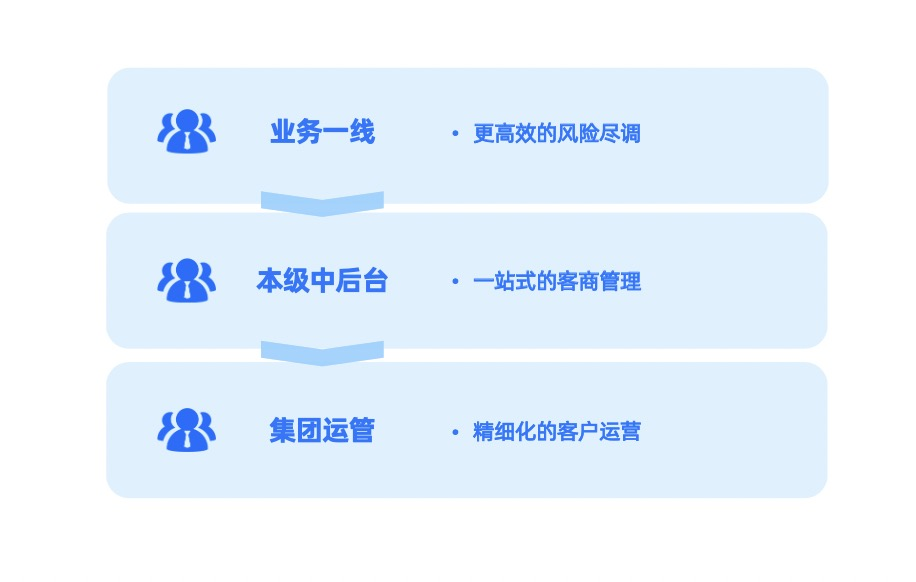
首先面向业务一线,蚂蚁数科主要提供便捷方面的能力。比如移动端的尽调工具,能够让业务员在出差的过程中,或者在现场仓库、与物流或车队的交流过程中,实时地基于手机端就可以进行信息的获取和填报,同时支持财报真实性及图片自动化识别的能力,实现线下非结构化数据和线上海量数据之间的融合。
其次面向中后台部门,构建了一站式的风险管理平台,把各个维度的客商数据即业务开展情况进行有效整合,并通过可视化的方式进行呈现,实现各个环节业务风险的识别、处置以及后续决策。这样就可以把原来靠人工经验去做的事情慢慢地沉淀到平台上来,使得整个公司在企业评估与风险把控方面有一套经验可以参考和传承。
对于集团层面来说,可能会关注比如红线的管理,蚂蚁数科会提供一套数据驱动的精细化运营手段。
举一个简单例子,之前服务的杭州热联集团,作为一个国有企业,在客户授信环节,针对年收入分别为500亿与1000亿的两家客户,有可能根据历史经验,给这两家企业的授信额度是一样的,但是通过数据分析之后,发现可以提高1000亿营收企业的授信额度。我们会把这两家企业放到平台上来,第一步会自动去识别欺诈模型的结果,如果存在欺诈,那这个企业会直接不予合作;否则就会进入到下一步,判断是否存在其他的负面信息,比如虚假的财报信息,如果都通过的情况下,会进入客商评级模型,不同等级的客户会配备不一样的行业指标。对于热联来说,则会定义客户额度基线,在不同的业务场景里,根据设置的基线实现额度更加有效与可量化的评估与授权。在原有的个人经验基础上,通过数据精细化来辅助判断,帮助业务做得更大更高。
同时,需要在底层构建一套数据资产体系,主要包含以下几个模块:
首先整合内外部的大量数据。这里的外部数据是指蚂蚁侧通过采集、购买或业务合作沉淀下来的各种类型的数据,如工商、司法、税务,包括知识产权等维度,内部数据是指和客户合作过程中客户自身的一些数据。
其次是数据集成。为了实现数据的集成、融合以及多元数据的安全共享,我们构建了一套多元数据枢纽能力来实现数据之间的链接和有效融合。
最后在数据整合之后,会对多维度的分散数据进行实体归户,将其挂靠到所属的企业、所属的行业以及所属的个体上面来,按照常规数据仓库的构建逻辑,划分成不同的主题,形成数据资产。再基于构建的基础数据层,围绕大宗行业的需要,构建行业本身的特定标签池。这是To B领域里面,传统行业下的数据构建逻辑。
此外,还会构建面向行业应用的指标框架。指标体系整体划分为三大类,第一类是公开指标,如工商、司法等公开的数据;第二类是合作客户的指标,如财务指标,这类数据一般存储在企业自身;第三类是蚂蚁侧基于机器学习算法,包括与客户合作过程中基于双方专家经验模型来沉淀的一些模型指标。
大宗行业的各家企业,对于客商准入都有自身的一套准入标准和准入规则体系,需要构建指标体系来进行支撑。基于指标体系,接下来要去构建企业评估的量化模型,如欺诈模型、准入模型、分类分级模型以及授信额度模型等。在模型的构建过程中,首先会结合行业属性整合多种维度的数据完成客户的行业分类,如互联网行业、文娱行业、零售消费行业等,之后基于行业客户的分布情况进行指标拆解。
如图中所示,包括经营状况指标、关联关系指标以及企业资质指标、舆情指标、违法违规指标等,再往下拆解这些指标背后所依赖的正负面的标签,基于标签再去拆解这些标签背后的具体数据表现。比如主营收入良好,那么这个标签良好的定义是什么?我们会去分析这个标签所处的行业占位,是高于行业平均还是低于平均,以及具体的营收情况。
通过层层拆解与下钻,让客户能够理解企业模型评估结果背后的逻辑,避免原来通过机器学习模型导致的黑盒无法解释的现象。这是量化评估在传统行业应用中非常不一样的地方,传统行业需要结果可解释,而不能仅仅是黑盒模型输出结果。接下来会把基础的数据资产标签和模型结果,呈现成业务可以理解的行业标签。
第一类是企业自身的风险,包括其基础信息,如所属的行业性质,是贸易型公司还是工厂或是矿山,以及行业分类是属于煤炭、钢铁,还是粮食或棉花等,同时会关注其财务状况,如偿债能力、盈利状况等,此外还有比如是否存在诉讼,近几年是否会发生一些高危的败诉等等这些风险表现,所有这些数据指标都是结合行业的特点去抽象和提炼的。另外一类是在企业的业务运行中关注的维度,就是纵观整个行业,该客商在行业中的占位、行业竞争力如何。
这些决定了与这个客户合作过程中应该采取的策略,比如要跟钢铁行业的中间客户合作,排除头部及尾部各十个,这里面就要对整个行业的分布、行业占位、行业竞争力做评估。将企业客商这些通用的风险特征,以及他所属行业相关的差异化特征,再结合实际业务应用中需要监控的特征,整合成这个行业的标签体系。
数据安全也是该解决方案中面临的比较大的难点,伴随着这两年数据安全和个人信息保护法重要度的提升,大部分企业,尤其是国央企对于自身数据安全方面有更多的顾虑。如何实现蚂蚁侧数据和客户侧数据的有效融合,从而实现整套服务方案的落地呢?
我们把整套数据服务体系分为两大块内容,一块是客户域,一块是蚁盾域,就是蚂蚁这边的数据域。要对两块数据进行有效融通,同时实现两块数据的高效运算。我们会在客户域做一个分布式的节点,服务于几百家客户就会有几百个不同的节点,这些节点都具备一套独立的数据采集处理,包括数据融合的能力,然后在蚁盾域做一个中心化的节点,两端通过分布式的协同决策来服务客户的业务应用。
这里面也同时会用到数据隐私计算的能力、分布式数据风险决策的引擎能力,以及数据质量保障上的能力等,通过这些能力共同作用实现蚂蚁在传统大宗行业的风险管控应用落地。
注:文/蚁盾,文章来源:蚁盾,本文为作者独立观点,不代表亿邦动力立场。
文章来源:蚁盾






